Kutatásaink részben alapkutatási, részben alkalmazott kutatási témájúak.
Az afázia a beszédközpont károsodása, amely érinti a beszédkészséget vagy annak megértését, valamint az olvasás vagy írás képességét. Az afáziában szenvedő emberek hosszabb reakcióidővel bírnak, és gyakran nem képesek kifejezni igényeiket, segítséget kérni, amikor erre szükségük lenne.
Az APH-ALARM egy olyan riasztórendszert kíván létrehozni az idősebb (55 év feletti), stroke-on átesett afáziával élő emberek számára, melynek köszönhetően visszanyerhetik és megőrizhetik függetlenségüket, képességeiket és méltóságukat miközben biztonságban és támogatottan érzik magukat. Az APH-ALARM egy átfogó biztonsági és univerzális monitorozást kínáló megoldás, amely riasztási (beleértve az automatikus riasztást) funkciót kínál a stroke-on átesett emberek számára. A kommunikációs nehézségekkel küzdő stroke-on átesett idősebb emberek segítése érdekében a rendszer segítséget kérő/riasztó funkciója kézzel, gesztusokkal és automatikusan is irányítható.
A megoldás a legváratlanabb és kritikusabb biztonsági vagy orvosi vészhelyzetben (akár alvás alatt is) használható, olyanokban, melyekben nem tudnák kifejezni magukat. A technológiai megoldás a EvoAid cég világszerte egyedülálló technológiáján és folyamatán alapul, amely egész nap képes segítséget nyújtani és figyelemmel kísérni az embereket. A rendszer a szükséges végfelhasználói adatok mobil alkalmazáson és az ágyérzékelőn keresztül történő gyűjtésén alapul, ami a modellek kiképzéséhez és optimalizálásához szükséges. A riasztórendszert kézzel, piktogramok segítségével, kézmozdulatokkal is vezérelheti a felhasználó, még akkor is, ha az okostelefon a zsebében vagy a táskájában van. Ezenfelül a rendszer rendelkezik automatikus riasztást kiváltó funkcióval is. Három ország (Magyarország, Ausztria és Portugália) technikai és végfelhasználói partnerei vesznek részt a rendszer kialakításában, fejlesztésében és értékelésében.
Link: Projektől részletesebben
Kutatásvezető: Dr. Németh Géza
Az AI4EU az Európai Unió mesterséges intelligencia (MI) projektje, amely egy európai MI-ökoszisztéma kifejlesztésére törekszik, összegyűjtve a rendelkezésre álló ismereteket, algoritmusokat, eszközöket és erőforrásokat. A 21 országot lefedő, 80 partnert tartalmazó, 20 millió eurós projekt 2019 januárjában indult, és három évig tart. Az AI4EU egyesíti az európai mesterséges intelligencia közösséget. Ez megkönnyíti a kollektív munkát az MI kutatásában, az innovációban és az üzleti életben Európában. Az AI4EU a szakértelem, tudás és eszközök megosztásával az MI-t mindenki számára elérhetővé teszi.
Az AI4EU fokozza az üzleti igények és a kutatási eredmények közötti átvitelt és felgyorsítja a növekedést. Segíteni fog az európai közösségnek abban, hogy globálisan vezető szerepet töltsön be mind a magasan fejlett, mind az emberközpontú MI-ben, élenjáró áttörést ígérve ezen a kulcsfontosságú technológiai területen.
Konzorcium 80 partnerrel
Link: https://www.ai4eu.eu
Kutatásvezető: Dr. Németh Géza
A projekt célja, hogy továbbfejlessze a HalloPflege+ kommunikációs portált egy Android alkalmazássá, amely innovatív beszédinterakciós modult is tartalmaz. Ez növeli az alkalmazás használhatóságát, idősotthonokban való felhasználhatóságát, és a családjaik és gondozóik közötti együttműködést.
A portál funkcionalitásának javítása és az új kommunikációs technológiák megvalósítása érdekében azt tervezzük, hogy a portált a webes verzióról egy natív Android-alkalmazássá alakítjuk át. Az első verzióban az Android portálnak ugyanazokat a funkcionális modulokat kell tartalmaznia, mint a webes verzió. A második lépésben új modulokat is fejlesztünk (pl. ételválasztás, virágok rendelése, szakmai kérdőívek). Ez növelheti a platform használati arányát, mivel jobb és egyszerűbb módot kínál a HalloPflege+ elérésére és használatára.
Partnerek:- BME-SmartLab
- SpeechTex Kft
- InterMedCon GmbH, Németország
Kutatásvezető: Dr. Németh Géza
A “Silent Speech Interface” (SSI) rendszerek a beszédtechnológia egyik forradalmi irányát képviselik, melynek során a hangtalan artikulációs mozgást valamilyen eszközzel felvesszük, majd ebből automatikusan beszédet generálunk, miközben az eredeti beszélő nem ad ki hangot. Ez a kutatási téma számos területen nagy jelentőséggel bír, ilyen többek között a beszédsérülteket segítő kommunikációs eszközök és a katonai alkalmazások. A tervezett projektben új módszereket javaslunk a beszéd közbeni artikuláció (elsősorban nyelv és ajkak) elemzésére és feldolgozására. A fő céljaink a következők: 1. az artikulációalapú fonémafelismerés teljesítményének alapos elemzése többféle artikulációt felvevő technológia kombinációjával; 2. a beszédkódolásban a spektrális szűrés javítása artikulációs adatok alapján; 3. a “felismerés-majd-szintézis” és a “direkt szintézis” módszerek tesztelése és javítása SSI témakörben. A fentiek során a beszélőszervek mozgásának leképezésére 2D ultrahangot, ajakvideót és elektromágneses artikulográfot (EMA) alkalmazunk. A kísérletek során nagy jelentőséggel bíró korszerű gépi tanulási módszereket használunk (különböző deep learning architektúrák). A fenti célok eléréséhez több magyar beszélőtől párhuzamos beszéd- és nyelvultrahang/artikulográf-adatot veszünk fel, elemezzük az artikulációs mozgást, különböző módokon modellezzük az artikuláció-akusztikum becslést, és végül objektív tesztekben és szubjektív kísérletekben valós felhasználókkal kiértékeljük a módszereket.
Partnerek:- BME-SmartLab
- MTA-ELTE Lendület Lingvális Artikuláció Kutatócsoport
- Szegedi Tudományegyetem, Informatikai Intézet
- MTA-SZTE Mesterséges Intelligencia Kutatócsoport
Kutatásvezető: Dr. Csapó Tamás Gábor
A honlap célja, hogy hozzáférhető adatokat biztosítson mindazoknak, akik érdeklődnek a beszéd és beszédtechnológia témaköre iránt. A honlap szorosan kapcsolódik az Akadémiai Kiadó gondozásában megjelent könyvhöz, amelynek címe: A MAGYAR BESZÉD - beszédkutatás, beszédtechnológia, beszédinformációs rendszerek. A beszédnek, mint irányfüggetlen, hangos információközlő eszköznek egyre nagyobb szerep jut az információs, digitális társadalomban. Ez főleg olyan megoldásokat kíván, amelyekben az emberek hangos szóval is beszélgethetnek a géppel. Az ilyen irányú kutatás, valamint szakoktatás támogatásához kívánunk hozzájárulni a honlapon közzétett adatokkal, programokkal. Ez az első nyilvános honlap, amelyen a magyar beszéd elemzésével kapcsolatos adatok szabadon hozzáférhetők.
Honlap: magyarbeszed.hu
Aloldalak:- Letölthető programok, adatok
- Interaktív anyagok
- Hangszimbólumok
- Kiejtési szótár
- Ismertető a könyvről
- A könyv tartalomjegyzéke
- A könyv szerzői

Az adatmennyiség robbanásszerű növekedésével, a GPU-k technológiai fejlődésével és a tudományterület új eredményeinek köszönhetően az elmúlt években a mélytanuló rendszerek, azon belül pedig a mély neurális hálózatok (Deep Neural Networks, DNN) a gépi tanulás egyik legjobban kutatott tématerületévé vált. A neuronháló mély rétegei a modellezni kívánt adatok különböző absztrakcióinak kinyerésére és osztályozására, predikciójára képesek. Ennek köszönhetően a mély neurális hálózatok a gépi látáson és beszéden túl már alkalmasak fordításra, zenei stílus automatikus osztályozására, felhasználói preferencia jóslására, felhasználó azonosítására, sőt, akár rajzolni és zenét komponálni is tudnak.
Laboratóriumunkban aktív kutatás folyik mind az alkalmazott, mind pedig az elméleti deep learning területén.
Kutatásvezető: Dr. Gyires-Tóth Bálint
A beszédtechnológiában sokszor az informatikától távolabb álló ismeretekre is szükség van: a beszéd modellezéséhez elengedhetetlen a hangképző szervek működésének áttekintése. A beszélő szervek közül a gége kitüntetett szerepet játszik, hiszen itt történik az alaphang képzése a tüdőből kiáramló levegő által, amely megrezegteti a hangszalagokat. Bizonyos beszédstílusokban (pl. levegős beszéd, suttogás, rekedtes beszéd) azonban a hangszalagok rezgése a normáltól eltérő is lehet. A gége rezgése mérhető a beszédjelből, de emellett speciális eszközzel, az ún. elektroglottográffal lehetőség van a hangszalagmozgás közvetlen mérésére is.
Kutatásunk során vokódert (más néven gerjesztési modellt) készítünk, mely használható 1) beszédstílus automatikus módosítására és 2) statisztikai parametrikus beszédszintézisre (pl. HMM alapú beszédszintézis). Vokóderen alapuló transzformációs eljárással lehetőség van a beszédjel módosítására (pl. rekedtesből normál beszéd). A HMM alapú beszédszintézisben a legújabb kutatási alkérdés, hogy a hangszalagok rezgését hogyan lehet folytonos, statisztikai modellezésre alkalmas paraméterekkel leírni.
Kutatásvezető: Dr. Csapó Tamás Gábor
Az elmúlt évtizedben a gépi szövegfelolvasó egyik meghatározó ága a statisztikai parametrikus beszédszintézis. Ekkor nem hullámformákat fűzünk össze, hanem a hangot beszédkódoló eljárásokkal (mint amilyen a mobiltelefonokban is van, vagy mint amit a Skype használ) paraméterekre bontjuk (ettől lesz parametrikus!) és ezeket modellezzük statisztikai, gépi tanuló eljárásokkal.
A mély neurális hálózatok az elmúlt években minden korábbi módszernél hatékonyabbnak bizonyultak. Laboratóriumunkban a nemzetközi tudományos és ipari megoldásokat követve, hazánkban egyedülálló aktív kutatás folyik mély neurális hálózat alapú beszédszintézis témakörben.
A mély MLP-től (Multi Layer Perceptron) kezdve, a modern rekurrens neuronhálózatokon át (Long Short Term Memory – LSTM, Gated Recurrent Unit – GRU) az autoencoderekig kísérleteket végzünk a sokrétű paraméterfolyamok pontos modellezésére. A modelleket nagykapacitású Nvidia Titan X-en és GTX 980-as GPU-kon tanítjuk, C, Python és LUA nyelven. Célunk minden korábbinál természetesebb és változatosabb gépi beszéd előállítása!
Kutatásvezető: Dr. Gyires-Tóth Bálint
{kind=link}
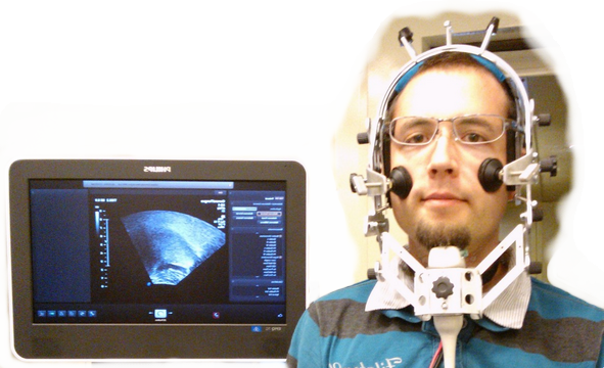
A szájüregről készült ultrahangos felvételek elemzésével láthatóvá tehetjük, hogyan "táncol" a nyelv beszéd közben! Az újabb ultrahangos technológiákat (nagyfelbontású és nagysebességű 2D / 3D / valós idejű 3D) azonban korábban nem alkalmazták beszédkutatási célokra. Részproblémák, amikkel foglalkozunk: nyelvkontúr követő algoritmusok tesztelése és megvalósítása, a nyelvmozgás és a beszédjel összehasonlítása, és annak vizsgálata, hogy ezek beszédtechnológiában hogyan használhatóak fel. A kutatás során párhuzamos beszéd és ultrahangos videó adatbázist elemzünk és dolgozunk fel.
Kutatásvezető: Dr. Csapó Tamás Gábor
Laboratóriumunkban aktív kutatás folyik az okostelefonok szenzoradatainak gépi tanuló módszerekkel történő osztályozására és predikciójára. Általános célunk az felhasználó viselkedési szokásainak elemzése és előrejelzése.
Az adott eszközön elérhető összes szenzoradatot (pl. gyorsulás, orientációs, fényérzékelő szenzor, hőmérséklet, WiFi hálózatok, Bluetooth hálózatok, stb.) dedikált alkalmazás segítségével gyűjtjük be és adatbázisban tároljuk el. Ezt követően az adatokat jellemzővektorokká alakítjuk klasszikus jelfeldolgozó eljárásokkal (pl. autokorreláció, kovariancia, Fourier transzformáció), majd modern algoritmusokkal osztályozzuk és becsüljük őket (pl. Support Vector Machine - SVM, K-Nearest Neightbors - KNN, Random Forrest, Deep Neural Network - DNN).
A kutatás legújabb iránya, hogy a szenzoradatok jellemzőit nem kinyerjük, hanem tanuljuk magukból az adatokból (feature learning) konvolúciós mély neurális hálózatokkal majd modern rekurrens neuronháló architektúrákon tanítjuk a modellünket (pl. LSTM – Long Short Term Memory, GRU – Gated Recurrent Unit). A számításokat nagykapacitású Nvidia Titan X-en és GTX 980-as GPU-kon végezzük Python és LUA nyelven.
Kutatásvezető: Dr. Gyires-Tóth Bálint
Laboratóriumunk magyar és idegennyelvű gépi szövegfelolvasó fejlesztésével, az ember-gép kapcsolat vizsgálatával és modern gépi tanulóalgoritmusok kutatásával foglalkozik.
Akadémiai és ipari partnereink sikeresen alkalmazzák megoldásainkat.
Kiemelt tartalmak
Kapcsolat
1117 Budapest, HUNGARY
Telefon: +36-1-463-3883
Fax: +36-1-463-3107
Email: smartlab@tmit.bme.hu
2025 © Minden jog fenntartva. A honlap minden tartalma és a honlapról letölthető dokumentumok (cikkek, bemutatók, diasorok, szoftverek, könyvek, stb.) a szerzői jog védelme alatt állnak. Ezek egészének vagy bármilyen részének újra felhasználása, terjesztése, megjelenítése csak a szerző(k) írásbeli beleegyezése esetén megengedett. (v914)